
大豆ミートに関する論文調査(2021年以降)
カテゴリー: 大豆蛋白・大豆ミート
投稿日: 2022-07-29
健康、蛋白質供給、環境負荷、食の多様性などから国内では大豆による代替肉、すなわち"大豆ミート"への関心が高まっています(大豆ミートのトレンド)。関連する特許出願数も増加しています(大豆ミートに関する特許調査)。
2022年2月24日、大豆ミート食品類の日本農林規格(JAS 0019)が制定されました。
日本における牛肉など食用肉の需給については、e-Statの食料需給表で確認することができます。 植物性の代替肉の影響については、このデータに今後現れてくるでしょう。特に環境負荷の高い牛肉の消費量への影響が注目されます。
今回はGoogle Scholarを用いて、2021年以降の大豆ミートに関係する研究論文について調査しました。
調査・解析方法
- 情報源: Google Scholar
- 期間指定: 2021年以降
- 検索項対象: title
- 検索ワード(日本語): 大豆 肉
- 検索ワード(英語) : soy meat
- 検索結果の保存: 検索結果ページをhtmlファイルで保存
- 検索結果の抽出と解析: Pythonで作成したプログラムを使用
日本の論文紹介
3件の論文が検索されました。2つは新規な肉様構造組織の製造法について、ひとつは大豆ミートを用いたメニューへの消費者への受容性についての論文です。
大豆タンパク質のミクロ構造制御を基盤技術とする新規肉様食品の開発
小林敬, 奥山奈名実, 西堀功規, 赤木美佳… - 日本食品工学 …, 2022 - jstage.jst.go.jp
不均一かつ方向性のある筋肉組織を想起させる食感を有し、従来の組織状植物タンパク質には乏しい油脂成分を豊富に含有する大型のブロック状の代替肉の製造手段を検討しています。
肉代替食品を志向した大豆タンパク質含有繊維の作製
長嶺信輔, 西堀功規, 中川究也, 小林敬 - 粉体工学会誌, 2021 - jstage.jst.go.jp
既存の肉代替食品よりも食肉の食感に近いものを得ることを目的とし,食肉の筋線維 を模した繊維を大豆タンパク質/アルギン酸ナトリウムの湿式紡糸により作製することを試みています。
Development and Acceptability of New Japanese Menus with Soy-based meat substitute
Yoko Ozaki. Tamami Kawakami. Saori Kamiya, Hitoshi Iizuka - Asian Journal of Dietetics, 2021
大豆たん白を用いた新しい食文化の確立とTSP料理の嗜好性を評価することを目的として、従来のレシピから、肉をSOY MEATに置き換えた30の新メニューへの受容性を調査しています。
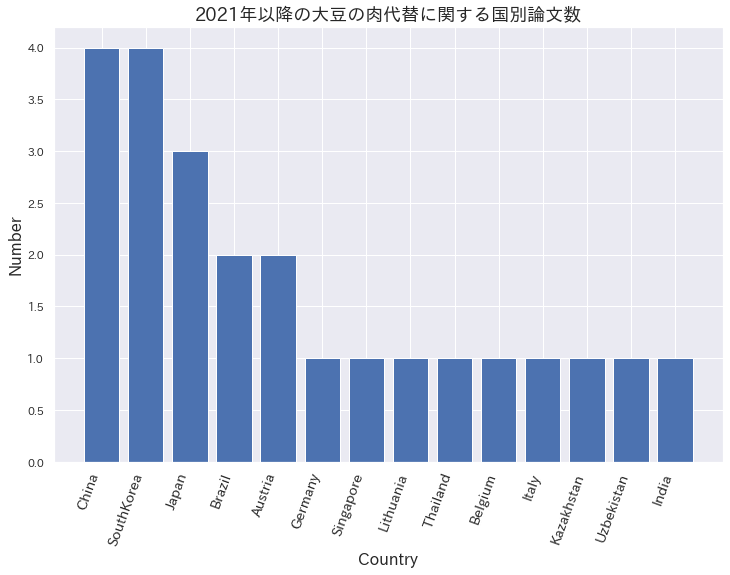
国別論文数
検索結果より関係のない論文と総説を除いた23論文について、国別に集計しました。
上位3カ国は中国、韓国、日本の順です。
PythonのプログラムでWordCloudという表示法を用いると
それぞれの国名の出現頻度に応じて文字サイズが大きく表示されます。色、配置はランダムです。

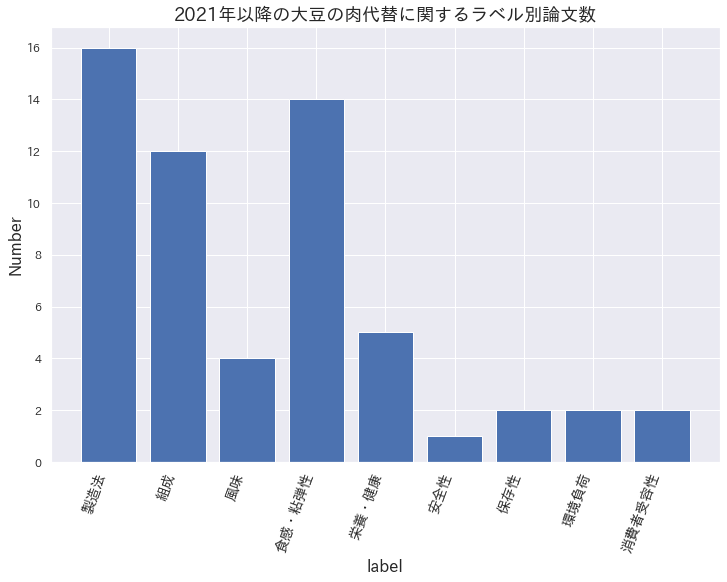
ラベル別論文数
23論文について、titleとabstractから各論文に9種のラベルを付け(重複あり)、ラベル別の論文数をプロットしました。全体的に製造法と組成についての論文が多く、また風味より食感が多いです。
titleに出現したワードのWordCloud表示
titleでの出現頻度に応じて各ワードが大きく表示されます。色、配置はランダムです。 titleに出現したword全体を直感的に楽しく把握しやすいです。日本語の論文のtitleはGoogle翻訳して用いました。

Pythonによるプログラムのコード
上記Google Scholarの検索結果ページからの情報の取得、プロット、WordCloudの表示に用いたPythonのコードです。
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
検索結果ページからの情報取得
各検索結果ページをhtmlファイルで保存し、PythonのプログラムでBeautifulSoupを使って、title, url, author-journalのテキスト情報を抽出します。
# Import
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import os
# htmlファイルの読み取り
soup = BeautifulSoup(open('soymeat_google_scholar_01.html'), 'html.parser')
# title情報を抽出してリストに代入
title_list = []
titles = soup.find_all('h3', class_='gs_rt')
for title in titles:
title_list.append(title.text)
# url情報を抽出してリストに代入
url_list = []
for title in titles:
ur = title.find('a')
url = ur.get('href')
url_list.append(url)
# author,journal情報を抽出してリストに保存
author_list= []
authors = soup.find_all('div', class_='gs_a')
for author in authors:
author_list.append(author.text)
# データフレームを作成して、CSVで保存
df = pd.DataFrame({'title': title_list,
'abstract': abst_list,
'author': author_list,
'url': url_list})
df.to_csv('daizu_meat_research.csv', index=False)
国別論文数をプロット
事前に各論文の掲載サイトページにてfirst authorの所属期間の国名を調べて、 列'country’として保存した daizu_meat_research.csv に追加して置きます。
# Install
!pip install japanize-matplotlib
# Import
from wordcloud import WordCloud
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import collections
# CSVファイルの読み込み
df = pd.read_csv('daizu_meat_research.csv')
# 各国名の出現数を取得
c = collections.Counter(df['country'])
# Plot
x, y = zip(*c.most_common())
fig, ax = plt.subplots(figsize=(12, 8))
ax.bar(x, y)
ax.set_title('2021年以降の大豆の肉代替に関する国別論文数', fontsize=18)
ax.set_xticklabels(x, rotation=70, ha='right', size = 14)
ax.set_xlabel('Country', size = 16, weight = "light")
ax.set_ylabel('Number', size = 16, weight = "light")
plt.show()
fig.savefig("country_num.png") #plotの保存
titleのWordCloud表示
# Import
from wordcloud import WordCloud
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# CSVファイルの読み込み
df = pd.read_csv('daizu_meat_research.csv')
# WordCloud用に列'title'の文字列の結合
txt_title = df['title'].str.cat(sep=' ')
# WordCloudのstopword(無視するword)の設定
stopwords = ['HTML', 'PDF','and','of','the','as','on','in','is','to','by',
'with','for','it','its','was','are','were','at','not','non','an',
'made','based','used']
# WordCloud表示
wordcloud = WordCloud(
max_font_size=60,
width=600, height=300,
background_color='white',
stopwords=stopwords
).generate(txt_title)
wordcloud.to_file("title_cloud_03.png")
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")