
大豆ミートに関する特許調査
カテゴリー: 大豆蛋白・大豆ミート
投稿日: 2022-06-30
健康、蛋白質供給、環境負荷などから国内では大豆による代替肉、すなわち"大豆ミート"への関心が高まっています。
また2022年2月24日、大豆ミート食品類の日本農林規格(JAS規格)が制定されました。
そこで大豆を原料とする肉代替素材開発に関する国内の特許について調査しました。
調査・解析方法
- 特許情報プラットホーム J-Plat Pat
- 検索項目: 要約/抄録
- 検索ワード: 大豆 x ( 肉代替 + 代替肉 + 肉様)
- プロットはダウンロードしたcsvファイルからPythonで作成(コードを記載)
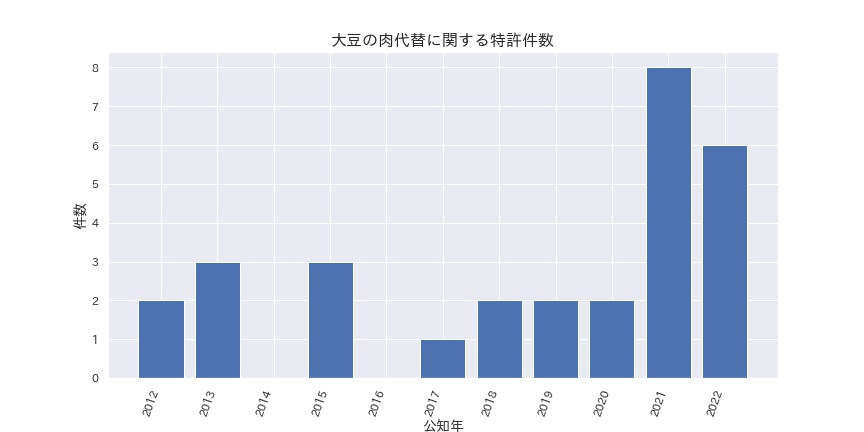
検索ヒット件数推移
2021年、2022年と特許件数が顕著に増加しています。
2012年以降に公知された出願企業と出願件数
不二製油㈱は以前より大豆蛋白の利用開発に力を入れています。
日本製粉㈱(2021年1月より㈱ニップンに社名変更)はパスタソース、冷凍食品向けでしょうか。
| 出願企業 | 出願件数 |
|---|---|
| 不二製油株式会社 | 5 |
| 日本製粉株式会社 | 3 |
| 伊藤ハム株式会社 | 3 |
| イビデン株式会社 | 3 |
| 昭和産業株式会社 | 2 |
| キユーピー株式会社 | 2 |
| 味の素株式会社 | 2 |
| 日本製紙株式会社 | 1 |
| オリエンタル酵母工業株式会社 | 1 |
| 日清オイリオグループ株式会社 | 1 |
| キユーピー株式会社 | 1 |
| MCフードスペシャリティーズ株式会社 | 1 |
| クラシエフーズ株式会社 | 1 |
| 日本食品化工株式会社 | 1 |
| 学校法人関東学院 | 1 |
| ソレイ リミテッド ライアビリティ カンパニー | 1 |
Pythonによるプログラムのコード
上記プロット・テーブルの作成に用いたPythonのコードです。
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
# Install
!pip install japanize-matplotlib
# Import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
# J-PlatPatからダウンロードしたcsvファイルの読み込み
df = pd.read_csv('特実_国内文献.csv')
print(df.shape)
print(df.info())
# '公知日'と'出願人'の列を抽出
df_ext = df.loc[:,['公知日','出願人/権利者']]
# '公知日'の値から年を抽出して新たな列'公知年'に代入
df_ext['公知年'] = df_ext['公知日'].apply(lambda x: int(str(x)[0:4]))
# 列'公知年'の値が2012年以降の行を抽出
df_ext = df_ext[df_ext['公知年'] > 2011]
# 列'公知年'の値を整数型から文字列型に変換
df_ext['公知年'] = df_ext['公知年'].astype(str)
# 公知年別特許件数プロット
## プロット用データフレームを作成
year_li = ['2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022']
number_li = []
for year in year_li:
try:
number_li.append(df_ext['公知年'].value_counts()[year])
except KeyError:
number_li.append(0)
year_df = pd.DataFrame({'公知年': year_li, '件数': number_li})
## プロット
xlabels = year_df['公知年'].to_list()
fig, ax = plt.subplots(figsize=(12, 6))
ax.bar(year_df['公知年'], year_df['件数'])
ax.set_title('大豆の肉代替に関する特許件数', fontsize=16)
ax.set_xticklabels(xlabels, rotation=70, ha='right')
ax.set_xlabel('公知年', size = 14, weight = "light")
ax.set_ylabel('件数', size = 14, weight = "light")
plt.show()
fig.savefig("patents_num.jpg") #plotの保存
# 出願企業別特許件数
shutugannin_li = df_ext['出願人/権利者'].unique().tolist()
for index, value in df_ext['出願人/権利者'].value_counts().iteritems():
print(index, ': ', value)