
豆腐に関する特許調査 ー日本、外国の比較(1)ー
カテゴリー: 大豆蛋白・大豆ミート
投稿日: 2022-11-11
健康、蛋白質供給、環境負荷、食の多様性などから国内外では大豆蛋白食品への関心が高まっています。忘れてならないのは、伝統的な大豆蛋白食品である豆腐です。
前記事では国内特許について報告しましたが、今回は日本出願の和文特許と外国出願の英文特許とを出願数推移、発明の名称と要約について比較分析しました。
検索された日本の特許は発明の名称と要約を一括でcsvファイルでダウンロードしましたが、外国特許はこれらはcsvファイルとしてダウンロードできないので、各特許を一つずつ開けてcsvファイルにコピペしました。これはかなりな手間なので、権利の関係などで難しいのかもしれませんが、改善していただければと思います。
外国特許は発明の名称と要約の英文をプログラムでグーグル翻訳して日本語に変えて比較分析に供しました。
多数の特許を比較するために、グーグルで開発された自然言語処理のBERTを使い、各特許の発明の名称と要約の文章から数百次元の数値ベクトルを計算します。これら高次元のベクトルを2次元のベクトル空間にマッピングして日本と外国の各特許の分布を見ることができるようにします。低次元化には、主成分分析とt-SNE法を用いました。今回は、日本特許と外国特許の発明の名称と要約の分布に違いがあるかに注目しました。
調査・解析方法
- 特許情報プラットホーム J-Plat Pat
- 検索対象:日本・和文、外国・英文
- 検索論理式: [豆腐/AB]*[A23L11/00/IP]、[tofu/AB]*[A23L11/00/IP]
AB:要約、IP:IPC(国際特許分類) - 公知日指定: 20130101〜202201116
- 検索結果: 日本和文194件、外国英文86件
- 分析はダウンロードしたcsvファイルからPythonプログラムで(BERTによるベクトル化と低次元化してプロットのPythonプログラムコードを記載)
発明名称を自然言語処理のBERTでベクトル化して比較
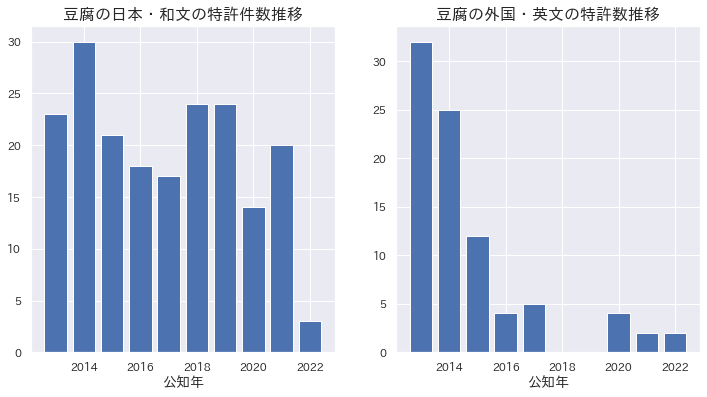
発明名称の主成分分析プロット
主成分分析はデータ全体の差異の大きい順に新たな次元を線形的に合成する次元の圧縮方法です。発明名称では日本特許と外国特許の分布に明確な違いは認めらませんでしたが、プロットの左下の領域ではやや外国特許が多いようです。
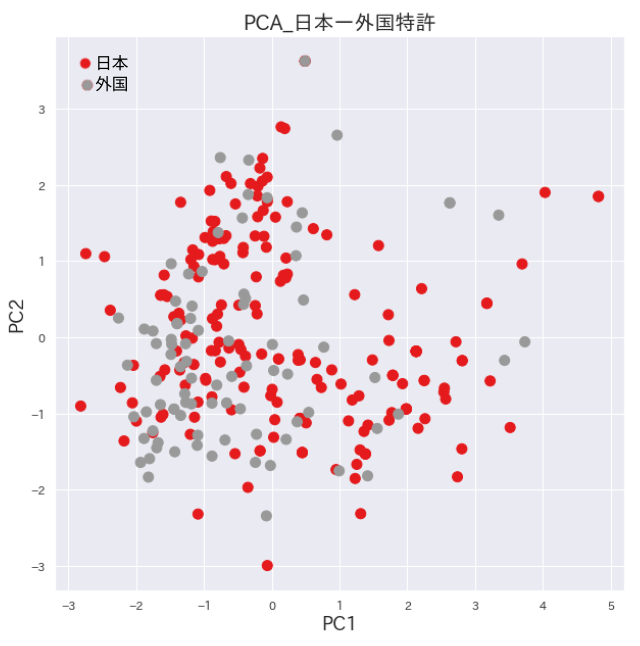
発明名称のt-SNEプロット
t-SNEは主成分分析より新しく開発された次元圧縮アルゴリズムです。高次元分布の局所的な構造を良く捉えながら大局的な構造も可能な限り捉えているとされています。どこまで大局に重点を置くかはperplexityと言うパラメータで調整します。
t-SNEによる下図の2次元のプロットでは左下に日本特許が専有している領域が認めらます。右上の領域では外国特許が多そうです。
自然言語処理して発明要約をベクトル化して比較
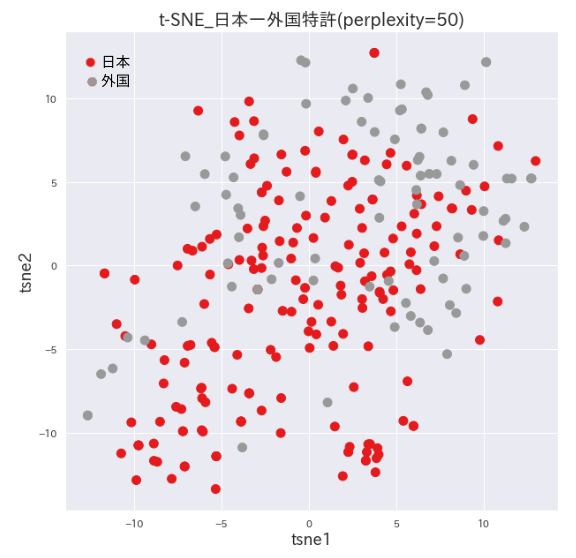
日本特許と外国特許の内容の違いの有無を要約の文章をベクトル化して高次元での分布の違いを上記の題名と同じく主成分分析とt-SNEで2次元のプロットで可視化してみました。両手法で分布の違いが認められました。これらの違いが特許の内容によるものか、国による表現の違いによるのか、英語文章を日本語に翻訳したことによるものかは次回の報告で調べてみます。
発明要約の主成分分析プロット
左下に日本特許の領域、右上に外国特許の多い領域に分かれています。
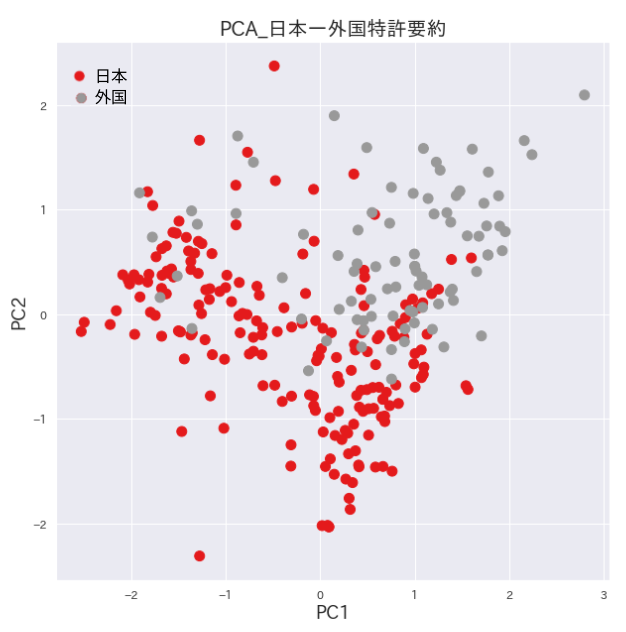
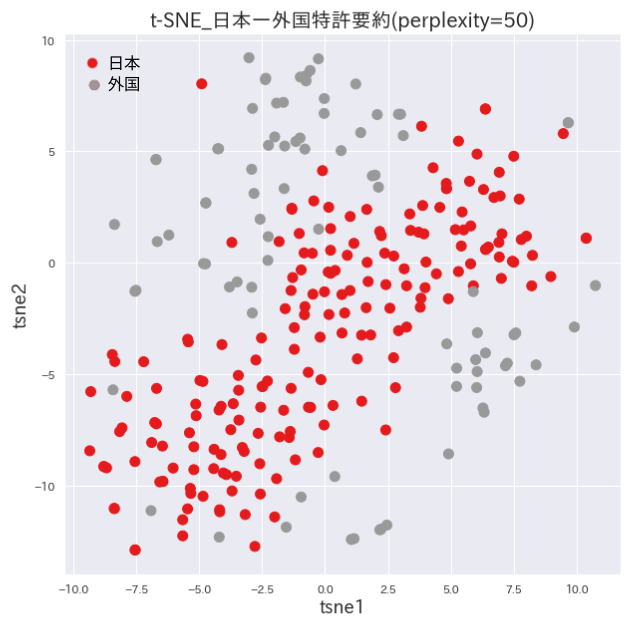
発明要約のt-SNEプロット
日本特許の領域を挟むように外国特許の領域が別れています。綺麗に分かれすぎていますので、機械翻訳した影響による可能性もありそうです。分かれた要因を精査する必要があります。
Pythonによるプログラムのコード
BERTによるベクトル化と主成分分析とt-SNEによるプロットのPythonのコードを記載します。
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
# Install
!pip install transformers==4.5.0 fugashi==1.1.0 ipadic==1.0.0
!pip install japanize-matplotlib
# Import
import random
import glob
from tqdm import tqdm
import pandas as pd
import numpy as np
import os
import re
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import torch
from torch.utils.data import DataLoader
from transformers import BertJapaneseTokenizer, BertModel
# J-PlatPatからダウンロードしたcsvファイルの読み込み
df_ja = pd.read_csv('特実_国内文献.csv')
df_en = pd.read_csv('特実_外国文献.csv')
# 各データフレームの構造を揃える
df_new_ja = pd.DataFrame({'文献番号': df_ja['文献番号'], 'title': df_ja['発明の名称']} )
df_new_en = pd.DataFrame({'文献番号': df_en['代表文献番号'], 'title': df_en['title_ja']} )
# ラベルの列"country"を追加して、2つのデータフレームを結合
country_ja = [1 for i in range(194)]
country_en = [2 for i in range(86)]
df_new_ja['country'] = country_ja
df_new_en['country'] = country_en
df = pd.concat([df_new_ja, df_new_en], axis=0)
# 発明名称のベクトル化
## トークナイザとモデルのロード
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
model = BertModel.from_pretrained(MODEL_NAME)
model = model.cuda()
## 各データの形式を整える
max_length = 256
sentence_vectors = [] # 文章ベクトルを追加していく。
for i, text in enumerate(df['title']):
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
encoding = { k: v.cuda() for k, v in encoding.items() }
attention_mask = encoding['attention_mask']
### 文章ベクトルを計算
### BERTの最終層の出力を平均を計算する。
with torch.no_grad():
output = model(**encoding)
last_hidden_state = output.last_hidden_state
averaged_hidden_state = \
(last_hidden_state*attention_mask.unsqueeze(-1)).sum(1) \
/ attention_mask.sum(1, keepdim=True)
### 文章ベクトルを追加
sentence_vectors.append(averaged_hidden_state[0].cpu().numpy())
## numpy.ndarrayにする。
sentence_vectors = np.vstack(sentence_vectors)
# 主成分分析による各特許の2次元分散プロット
sentence_vectors_pca = PCA(n_components=2).fit_transform(sentence_vectors)
plt.figure(figsize=(10,10))
plt.scatter(sentence_vectors_pca[:,0],
sentence_vectors_pca[:,1],
s=100, c=df['country'], cmap='Set1'
)
plt.title('PCA_title 日本vs外国特許', fontsize=20)
plt.xlabel("PC1", fontsize=18)
plt.ylabel("PC2", fontsize=18)
plt.show()
# t-SNEによる2次元分散プロット
sentence_vectors_tsne = TSNE(n_components=2, random_state = 0, perplexity = 30, n_iter = 10000).fit_transform(sentence_vectors)
plt.figure(figsize=(10,10))
plt.scatter(sentence_vectors_tsne[:,0],
sentence_vectors_tsne[:,1],
s=100, c=df['country'], cmap='Set1'
)
plt.title('t-SNE_日本ー外国特許', fontsize=20)
plt.xlabel("tsne1", fontsize=18)
plt.ylabel("tsne2", fontsize=18)
plt.show()