
穀物、木材、大豆油と原油の価格推移データ分析 EDA
カテゴリー: 大豆蛋白・大豆ミート、データサイエンス
投稿日: 2022-10-26
世界的な穀物などの価格高騰で日本の食料品の価格も上昇しています。
そこで、中長期の穀物、コーヒー、大豆油、木材、石油原油のこれまでの価格推移と、各価格間の相関を調べてみました。
データサイエンスではデータを収集、分析して、予測や分類のための機械学習モデルを作成します。データの分析をEDA(Exploratory Data Analysis:探索的データ分析)と言います。
データの収集と分析
- データ収集したサイト: macrotrends.net
- 収集した価格データ。下記のページからcsvファイルでダウンロードしました。
- 大豆:Soybean Prices - 45 Year Historical Chart
- コーン:Corn Prices - 59 Year Historical Chart
- 小麦:Wheat Prices - 40 Year Historical Chart
- オーツ麦:Oats Prices - 45 Year Historical Chart
- コーヒー:Coffee Prices - 45 Year Historical Chart
- 大豆油:Soybean Oil Prices - 45 Year Historical Chart
- 木材:Lumber Prices - 50 Year Historical Chart
- 石油原油:Crude Oil Prices - 70 Year Historical Chart
- データの分析:Pythonで作成したプログラムで
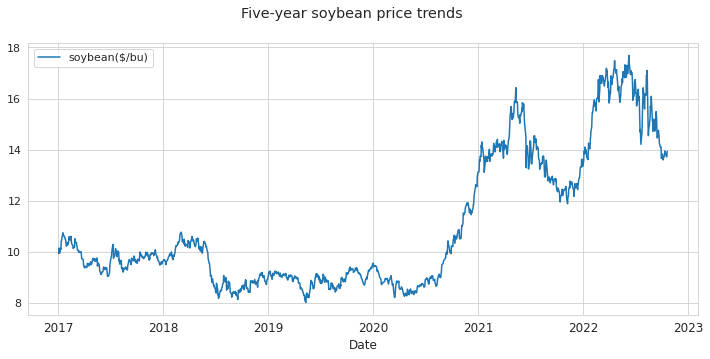
大豆の直近5年間の価格推移
大豆の価格は、2020年後半から上昇して2021年前半と2022年前半にピークがあります。穀物の価格に影響する要因としては、需要と供給、エネルギーコスト、物流、産地の状況などが挙げられます。2020年以降では新型コロナウイルス感染拡大による経済活動の停滞などの影響も考えられます。生産面では、栽培面積、気候変動が影響します。これら、考えられる要因を説明変数としてデータ化して価格の予測学習モデルを作成することがデータサイエンスの目的になります。
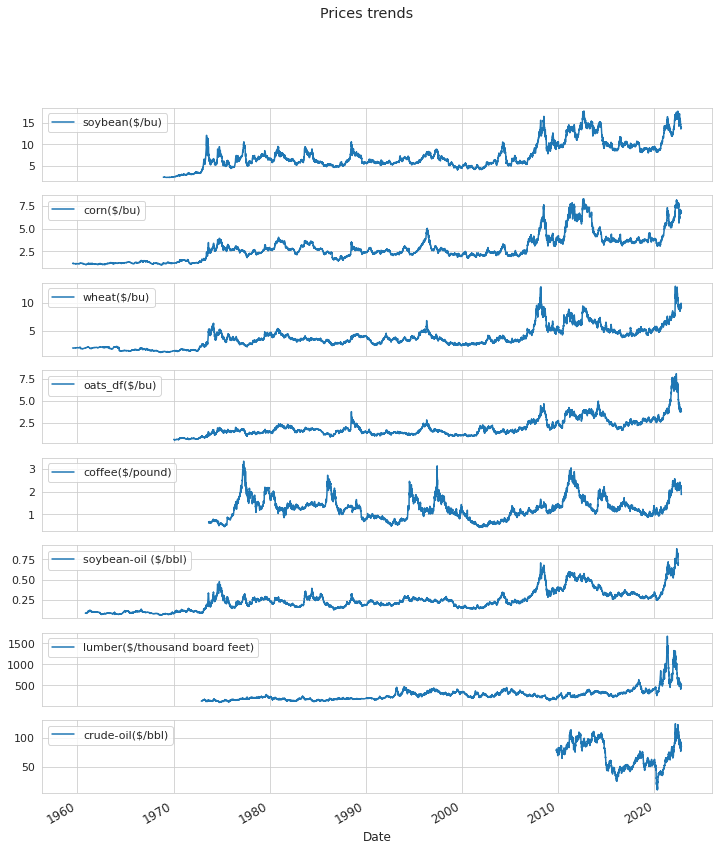
約50年間の大豆、他の穀物、大豆油、木材、石油原油の価格推移
macrotrends.netから今回収集した大豆、コーン、小麦、オーツ麦、コーヒー、大豆油、木材、石油原油の価格データ推移のプロットです。
大豆では1970年代からのデータで、今回に匹敵あるいはそれ以上の大きな価格上昇が2010年前後にも起きています。この頃の円の対ドルレートは80円前後で、今は140円台まで円安になっていますから、日本国内の価格上昇の圧力は強いです。
コーン、小麦、オーツ麦は大豆とほぼ似た推移をしています。大豆油も同様の傾向です。注視すべきは、穀物の価格変動が2000年以降顕著に大きくなっていることです。
コーヒーは数回の大きな上昇が起きています。木材(lumber)は2020年以前と比べて今回のみ顕著に大きな上昇です。
石油原油(crude oil)は2010年以降のデータしか取得できませんでしたが、穀物と大豆油と似た動向を示しているようです。
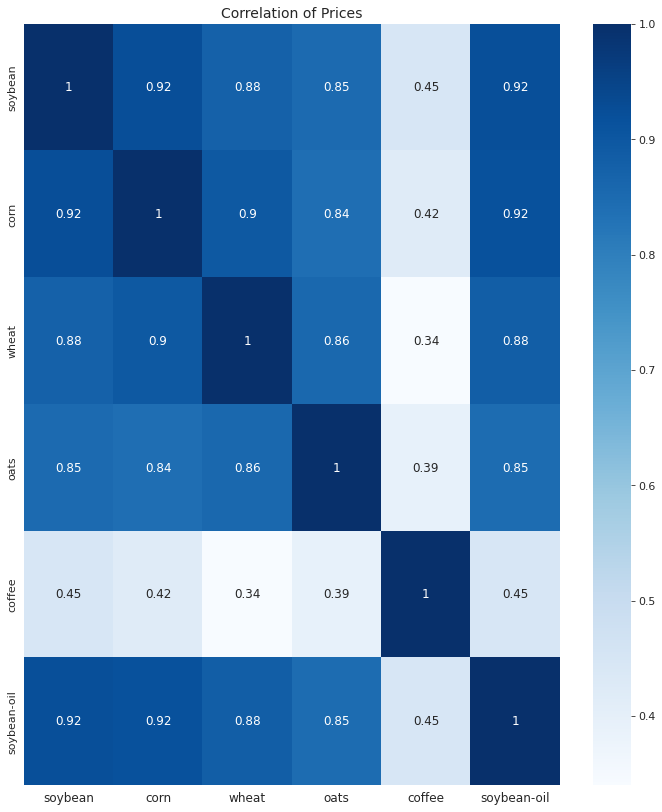
約50年間(1973-08-20から2022-06-30)の各穀物価格間の相関を可視化
各価格間の相関係数をヒートマップでプロット
各穀物の価格間の相関をプロットしました。データが揃っている1973年8月20日から2022年6月30日のデータで相関係数を計算しています。
約50年に渡る長期のデータではコーヒー以外の穀物、すなわち大豆、コーン、小麦、オーツ麦と大豆油との間の相関係数は0.85〜0.92と高い相関を示しています。主な価格変動要因が共通で、なお各穀物の価格間で影響しあっていることが推察されます。コーヒーと他の穀物との相関係数は0.34〜0.45で、共通する変動要因の他に別な変動要因があると推測されます。
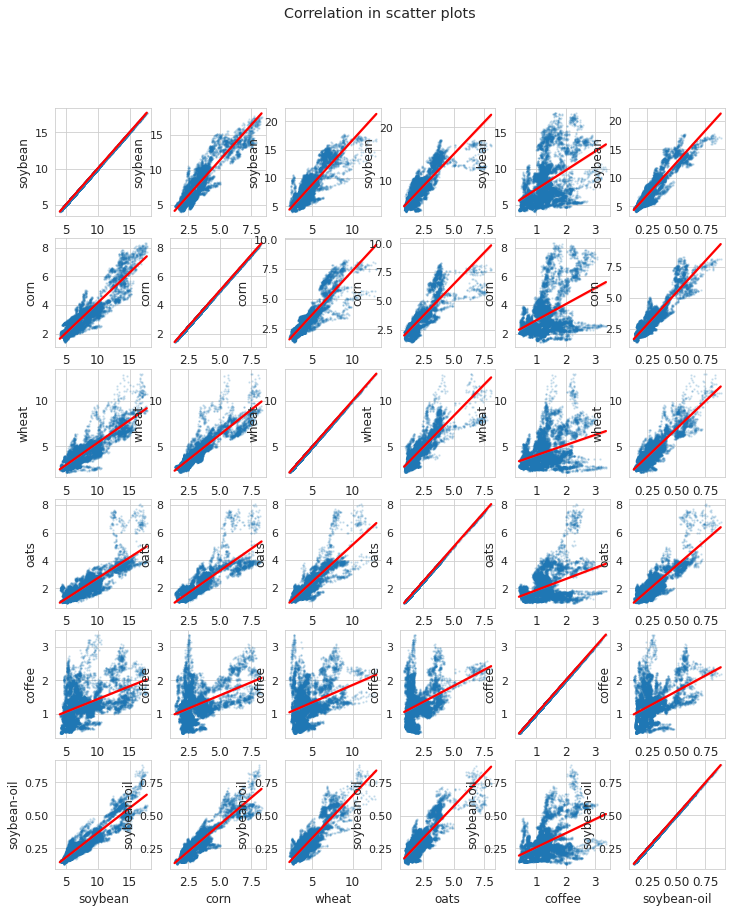
相関を分散図で表示
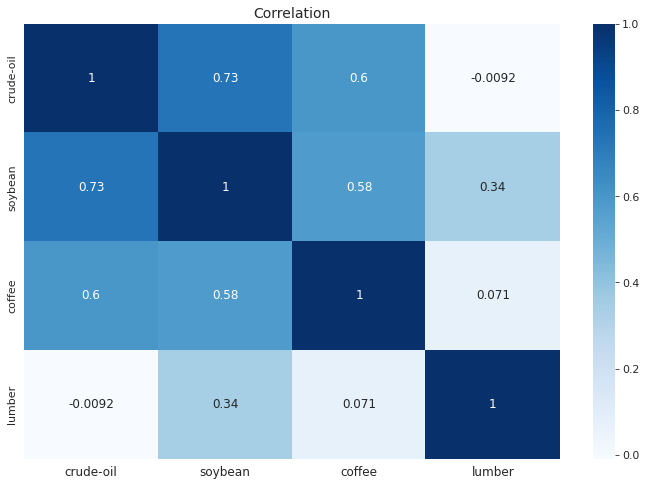
直近10年間の石油原油と大豆、コーヒー、木材との価格の相関係数ヒートマップ
石油原油と大豆、コーヒー、木材との相関係数を計算すると、それぞれ0.73, 0.6, -0.0092となりました。大豆、コーヒーはある程度石油原油と相関があり、石油原油の価格の影響を受けている可能性が示唆されます。一方、木材は石油との相関はありませんでした。木材の今回の価格上昇には別な要因の可能性があります。
Pythonによるプログラムのコード
上記プロット作成に用いたPythonのコードです。
データはmacrotrends.netでダウンロードしたcsvファイルを用いています。
プロットのコードはKaggleに投稿されている下記のコードを参考・修正して作成しました。
Commodities prices by MARCELO COELHO DE LIMA
(under the Apache 2.0 open source license)
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
Import
# Import
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
csvファイルデータの読み込み
# ファイルのパスリストの作成
dir_l = []
for filenames in os.walk('input/'):
for file in filenames[2]:
#print(file)
dir = filenames[0] + file
dir_l.append(dir)
# csvファイルをデータフレームに読み込み
soyoil_df = pd.read_csv(dir_l[0], parse_dates=['date'] , skiprows=15)
soy_df = pd.read_csv(dir_l[1], parse_dates=['date'] , skiprows=15)
corn_df = pd.read_csv(dir_l[2], parse_dates=['date'] , skiprows=15)
wheat_df = pd.read_csv(dir_l[3], parse_dates=['date'] , skiprows=15)
coffee_df = pd.read_csv(dir_l[4], parse_dates=['date'] , skiprows=15)
oats_df = pd.read_csv(dir_l[5], parse_dates=['date'] , skiprows=15)
crudeoil_df = pd.read_csv(dir_l[6], parse_dates=['date'] , skiprows=15)
lumber_df = pd.read_csv(dir_l[7], parse_dates=['date'], skiprows=15)
データの前処理
# 列'date'をindexに、各列名を変更
soyoil_df.set_index('date', inplace=True)
soyoil_df.rename(columns={' value': 'soybean-oil'}, inplace=True)
soy_df.set_index('date', inplace=True)
soy_df.rename(columns={' value': 'soybean'}, inplace=True)
corn_df.set_index('date', inplace=True)
corn_df.rename(columns={' value': 'corn'}, inplace=True)
wheat_df.set_index('date', inplace=True)
wheat_df.rename(columns={' value': 'wheat'}, inplace=True)
coffee_df.set_index('date', inplace=True)
coffee_df.rename(columns={' value': 'coffee'}, inplace=True)
oats_df.set_index('date', inplace=True)
oats_df.rename(columns={' value': 'oats'}, inplace=True)
crudeoil_df.set_index('date', inplace=True)
crudeoil_df.rename(columns={' value': 'crude-oil'}, inplace=True)
lumber_df.set_index('date', inplace=True)
lumber_df.rename(columns={' value': 'lumber'}, inplace=True)
プロットの設定
texts_base_context = {
"font.size": 12,
"axes.labelsize": 12,
"axes.titlesize": 14,
"xtick.labelsize": 12,
"ytick.labelsize": 11,
"legend.fontsize": 11,
"legend.title_fontsize": 12,
}
base_context = {
"axes.linewidth": 1.25,
"grid.linewidth": 1,
"lines.linewidth": 1.5,
"lines.markersize": 6,
"patch.linewidth": 1,
"xtick.major.width": 1.25,
"ytick.major.width": 1.25,
"xtick.minor.width": 1,
"ytick.minor.width": 1,
"xtick.major.size": 6,
"ytick.major.size": 6,
"xtick.minor.size": 4,
"ytick.minor.size": 4,
}
#plt.rcParams["figure.figsize"] =(12,12)
plt.rcParams["legend.loc"] = 'upper left'
sns.set_style('whitegrid')
sns.set_context(texts_base_context,base_context)
大豆の直近5年間の価格推移のプロット
soy_5year = soy_df['2017-01-01':]
plt.rcParams["figure.figsize"] =(12,5)
fig, ax = plt.subplots()
ax.plot(soy_5year)
ax.legend(['soybean($/bu)'])
plt.xlabel('Date')
fig.suptitle("Five-year soybean price trends")
plt.show()
約50年間の大豆、他の穀物、大豆油、木材、石油原油の価格推移をプロット
plt.rcParams["figure.figsize"] =(12,14)
fig, ax = plt.subplots(nrows=8, sharex=True)
soyoil_df.plot(ax=ax[5])
soy_df.plot(ax=ax[0])
corn_df.plot(ax=ax[1])
wheat_df.plot(ax=ax[2])
coffee_df.plot(ax=ax[4])
oats_df.plot(ax=ax[3])
crudeoil_df.plot(ax=ax[7])
lumber_df.plot(ax=ax[6])
ax[5].legend(['soybean-oil ($/bbl)'])
ax[0].legend(['soybean($/bu)'])
ax[1].legend(['corn($/bu)'])
ax[2].legend(['wheat($/bu)'])
ax[4].legend(['coffee($/pound)'])
ax[3].legend(['oats_df($/bu)'])
ax[7].legend(['crude-oil($/bbl)'])
ax[6].legend(['lumber($/thousand board feet)'])
fig.suptitle('Prices trends')
plt.xlabel('Date')
plt.show()
各価格間の相関を可視化
# 各データフレームを一つに結合、列順変更
df_join = coffee_df.join([soy_df, corn_df, wheat_df, oats_df, soyoil_df ])
df_join = df_join.reindex(columns=['soybean', 'corn', 'wheat', 'oats', 'coffee', 'soybean-oil'])
df_join.info()
# データ期間を設定、欠損値を直前の値で埋める
df_result = df_join[:'2022-06-30']
df_result.fillna(method='ffill', inplace=True)
# 各価格間の相関係数をプロット
sns.heatmap(df_result.corr(), annot=True, cmap="Blues")
plt.title('Correlation of Prices')
# 各価格間の相関を散布図で可視化
fig, ax = plt.subplots(6,6)
a=0
b=0
for i in df_result.columns:
for j in df_result.columns:
sns.regplot(x=i, y=j,data=df_result,ax=ax[a,b],scatter_kws={'alpha':0.15,'s':2}, line_kws={'color': 'red'},order=1)
if (a