
木質バイオマス発電に関する研究論文・発表
カテゴリー: 森林資源
投稿日: 2022-09-22
持続可能な社会の実現を目指し、森林の整備、エネルギー自給率の向上、環境に優しい素材の供給源としての森林資源の利用が注目されます。しかしながら、この分野の情報は普段なかなか目に触れる機会が少ないです。
そこで、森林資源の利用について、行政の動き、事業者の状況、特許、研究論文について調査しています。
今回は、木質バイオマス発電に関する2022年の研究論文について調査しました。
調査方法
- 情報源: Google Scholar
- 検索項目: 論文タイトル
- 検索期間: 2013〜2022年
- 日本語論文の検索ワード: 木質バイオマス発電
- 英語論文の検索ワード: woody biomass power generation
2022年度の研究論文
3件の日本語論文と1件の英語論文・発表が検索されました。
木質バイオマス発電のあゆみと今後の展望
澤田直美 - 電気学会誌, 2022 - jstage.jst.go.jp
2.6 木質バイオマス発電の本格導入 東日本大震災当日に閣議決定された FIT 制度では,価格は新設される「調達価格等算定委員会」の意見を参考とし経済産業大臣が決定することとなった.・・
冷却塔方式 復水器冷却水系統最適制御システム─ 再生可能エネルギー木質バイオマス発電設備の普及に向けて─
清水寿昭 - 紙パ技協誌, 2022 - jstage.jst.go.jp
株式会社中部プラントサービスは事業性改善に取り組んでいる。最も効果が得られたのは「冷却塔方式、復水器冷却水系統最適制御システム」。発電設備の所内動力を削減するとともに売電量を増加させるという。
P-01 日本全国における木質バイオマス発電のための未利用木材利用可能量推計
有賀一広, 松岡佑典, 林宇一… - … 論文集 第 17 回バイオマス …, 2022 - jstage.jst.go.jp 研究発表(ポスター発表)
本研究では、地域の森林計画に基づき設定された育林処方と、傾斜角や高低差などの地形条件に基づき設定された施業体系をGISを用いて、スギ、ヒノキ、マツ、カラマツ林の造林、伐採などの収支と、切り株価格を算出しました。そして、2020年6月末にFITで稼働する木質バイオマス発電所向けの未利用材を、採算性の高い小区画からの供給可能量として試算した。また、補助率100%の森林確保を考慮すると、日本全体の需要に見合った利用可能量となった。
Action of Public-Private Partnership Woody Biomass Gasification Power Generation in Nanbu-Town, Yamanashi prefecture
T Sato, A Watanabe, I Mochizuki… - The Japanese Forest …, 2022 - jstage.jst.go.jp 学術講演集原稿
山梨県南部町では、2021年よりガス化による木質バイオマス発電事業を実施している。ダウンドラフト方式によるガス化システムで、760KWの電力と約2000KWの熱量産出。原料は、合同会社南部GREEN ENERGYが年間7000トンの素材をチップ化した。
引用元数(他の論文での引用数)の多い論文の紹介
他の論文での引用数の多い論文はいずれも原料、特に未利用材の供給に関するものでした。
再生可能エネルギー固定価格買取制度を利用した木質バイオマス発電事業における原料調達価格と損益分岐点の関係
柳田高志, 吉田貴紘, 久保山裕史, 陣川雅樹 - 日本エネルギー学会誌, 2015 - jstage.jst.go.jp
引用元 18
未利用材の供給不足が懸念される木質バイオマス発電
安藤範親 - 農林金融, 2014 - nochuri.co.jp
引用元 10
栃木県における木質バイオマス発電のための長期的な未利用材利用可能量推計
山本嵩久, 有賀一広, 古澤毅, 當山啓介, 鈴木保志… - 日本森林学会 …, 2017 - jstage.jst.go.jp
引用元 9
北海道における木質バイオマス発電所向け未利用材の供給ポテンシャルの試算
酒井明香, 津田高明, 八坂通泰 - 日本森林学会誌, 2017 - jstage.jst.go.jp
引用元 8
論文タイトルに出現した都道府県、その他地名と出現回数
地名の出現頻度から、木質バイオマス発電に関する調査・研究の盛んな地域が見えてくるかもしれません。地名の抽出には、自然言語処理技術のBERTを使っています。
- 4回出現:栃木県
- 3回出現:北海道、高知県、九州、北関東
- 2回出現:岩手県、宮崎県、福島県
- 1回出現:大分県日田、和歌山県、山形県、北海道紋別市、水俣市、東北、三重県、富山県、兵庫県、栃木県那須野が原
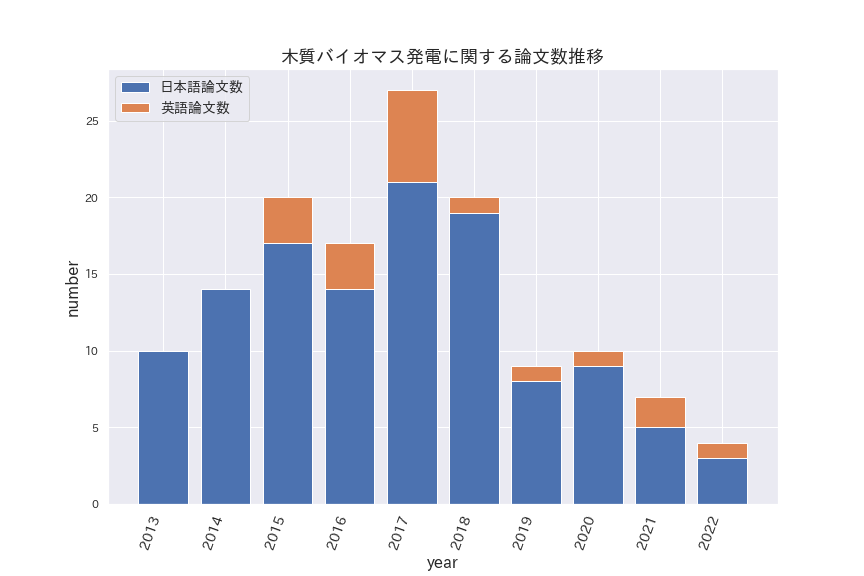
木質バイオマス発電に関する研究論文数の推移
2013〜2022年の10年間で138の論文が検索されました。2017年をピークとして減少しています。日本語と比べて英語の論文数が少く、国外では研究が少ないようですが、検索ワードの"power generation"が適切でなかった可能性もあります。
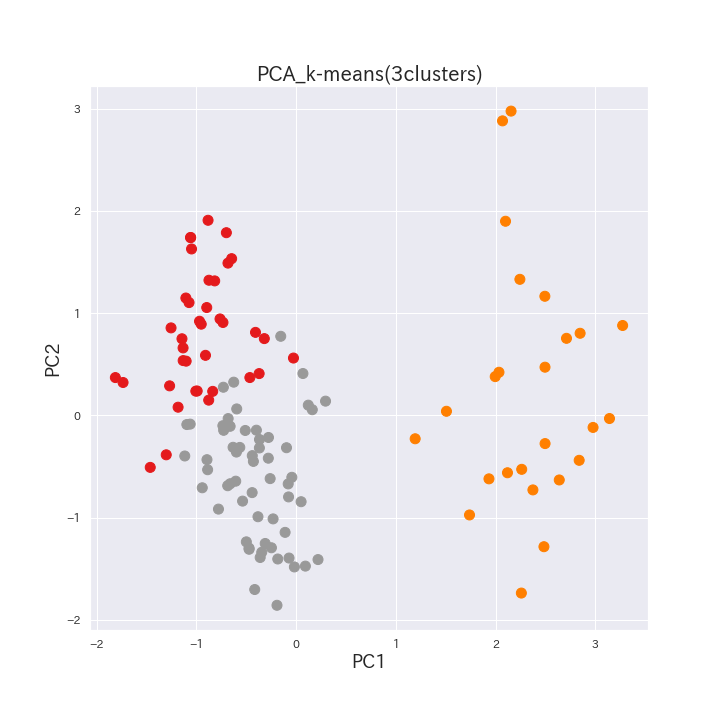
日本語論文のクラスタリングとラベリング
2013年以降の120の日本語論文について、各論文タイトルを自然言語処理によりベクトル化して3つのクラスタに分類、特徴付けを試みました。
BERTによる各論文タイトルの自然言語処理によるベクトル化
BERTはGoogle検索エンジンのアルゴリズムにも使われている自然言語処理技術です。2018年にGoogleから公開されました。BERTにより、文章の理解が向上して、文章による検索性能が向上したとされています。Pythonのライブラリとしても公開されて、文章・会話などの解析、AIのコアとなる機械学習モデルの作成に一般的に良く使われるようになりました。
BERTに各論文のタイトルのテキストデータを入力することで、数百次元の数値ベクトルを得ることができます。ベクトル化されたタイトルデータは各種の多変量解析にかけることができます。今回は、主成分分析とk-means法でクラスタリングを行いました。最後の項目にPythonによるプログラムコードを載せています。
主成分分析とk-meansによるクラスタリング
k-means法で3つにクラスタリングした結果を主成分プロット上で3色に色分けしました。第一成分と第二成分の2次元主成分プロット上で3つのクラスタがほぼ分離できています。
各クラスタの特徴付け
k-meansによるクラスタリングで分けられた3クラスタについて、「木質」「バイオマス」「発電」を除いた出現頻度の多い語彙から特徴付け(ラベリング)を試みました。
今回ベクトル化に使用したBERTの日本語学習モデルは東北大から公開された汎用モデルなので必ずしも正しくクラスタリングされているとは限りませんが、木質バイオマス発電に詳しい専門家によるラベリングしたデータでファインチューニングするとより正確な分類ができるようになると思われます。
上記で紹介した2022年の文献の、「木質バイオマス発電のあゆみと今後の展望」はクラスタ1に、「冷却塔方式 復水器冷却水系統最適制御システム─ 再生可能エネルギー木質バイオマス発電設備の普及に向けて」と「日本全国における木質バイオマス発電のための未利用木材利用可能量推計」はクラスタ3にクラスタリングされています。
| クラスタ名 | 頻出語彙 | ラベル |
|---|---|---|
| クラスタ1 37件 |
'現状', '課題', '制度', '特集', '展望', '事業', '所', '県', '燃料', '日本', '今後' | 現状の課題と展望についての レビュー |
| クラスタ2 25件 |
'可能', '性', '利用', '研究', '材', '供給', '燃料', '県', '所', '課題', '資源' | 可能性研究 |
| クラスタ3 58件 |
'利用', '材', 'システム', '量', '評価', '可能', '事業', '県', 'ため', '推計', '地域' | 木質原料、未利用材評価 |
各クラスタの出現頻度によるWordCloud表示
クラスタ1のWordCloud

クラスタ2のWordCloud

クラスタ3のWordCloud

Pythonによるプログラムのコード
上記論文タイトルのベクトル化と主成分プロットの作成に用いたPythonのコードです。
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境:Google Colaboratory
ハードウェア アクセラレータ: GPU
日本語論文タイトルのBERT自然言語処理によるベクトル化とクラスタリング
Google Scholarの検索結果ページをhtmlファイルで保存し、Phytonで読み込みます。
#Install
!pip install transformers==4.5.0 fugashi==1.1.0 ipadic==1.0.0
!pip install japanize-matplotlib
#Import
import random
import glob
from tqdm import tqdm
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
import os
import re
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
import torch
from torch.utils.data import DataLoader
from transformers import BertJapaneseTokenizer, BertModel
# BERTの日本語モデル
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
# htmlファイルの読み込みとタイトルを抽出してリストに
f_list = glob.glob("./input/*")
title_list = []
for file in f_list:
print(file)
soup = BeautifulSoup(open(file), 'html.parser')
# title情報を抽出してリストに代入
titles = soup.find_all('h3', class_='gs_rt')
for title in titles:
title_list.append(title.text)
# 論文idリスト
r = range(1,121)
id = list(r)
# タイトルとidをデータフレームに
df = pd.DataFrame({'id': id, 'title': title_list})
# タイトルの前処理(不要な文字の削除)
title_list_del = []
for title in title_list:
title_del = re.sub("[a-xA-Z0-9_]","", title)
title_del = re.sub("[!-/:-@[-`{-~]","",title_del)
title_del = re.sub(u'\n\n', '\n', title_del)
title_del = re.sub(u'\r', '', title_del)
title_list_del.append(title_del)
# ベクトル化
## トークナイザとモデルのロード
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
model = BertModel.from_pretrained(MODEL_NAME)
model = model.cuda()
## 各データの形式を整える
max_length = 256
sentence_vectors = [] # 文章ベクトルを追加していく。
for i, text in enumerate(title_list_del):
#print(i)
encoding = tokenizer(
text,
max_length=max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
encoding = { k: v.cuda() for k, v in encoding.items() }
attention_mask = encoding['attention_mask']
# 文章ベクトルを計算
# BERTの最終層の出力を平均を計算する。
with torch.no_grad():
output = model(**encoding)
last_hidden_state = output.last_hidden_state
averaged_hidden_state = \
(last_hidden_state*attention_mask.unsqueeze(-1)).sum(1) \
/ attention_mask.sum(1, keepdim=True)
# 文章ベクトルを追加
sentence_vectors.append(averaged_hidden_state[0].cpu().numpy())
## numpy.ndarrayにする。
sentence_vectors = np.vstack(sentence_vectors)
# k-meansによる3つのクラスタリングと主成分分析
model = KMeans(n_clusters=3, random_state=0, init='random') # initを省略すると、k-means++法が適応される(randomではk-means法が適応)
model.fit(sentence_vectors)
clusters = model.predict(sentence_vectors) # データが属するクラスターのラベルを取得
# dfにcluster番号を列として追加
df['cluster'] = clusters
# csvファイルで保存
df.to_csv('kmeans3_pca_02.csv')
# 10-6 主成分分析
sentence_vectors_pca = PCA(n_components=2).fit_transform(sentence_vectors)
plt.figure(figsize=(10,10))
plt.scatter(sentence_vectors_pca[:,0],
sentence_vectors_pca[:,1],
s=100, c=clusters, cmap='Set1'
)
plt.title('PCA_k-means(3clusters)', fontsize=20)
plt.xlabel("PC1", fontsize=18)
plt.ylabel("PC2", fontsize=18)
plt.savefig('k-means3_pca.png') # Plotを画像ファイルで保存
plt.show()