
大豆ミートの2023年の市場と研究開発動向
カテゴリー: 大豆蛋白・大豆ミート、日本の研究開発動向の見える化
投稿日: 2024-02-01
健康、蛋白質供給、環境負荷などから国内では大豆による代替肉、すなわち"大豆ミート"への関心が高まっています。2022年2月24日には大豆ミート食品類の日本農林規格(JAS規格)が制定されました。
日本発の大豆ミートの技術はアジアからさらには欧米まで広く大きな市場で利用されるポテンシャルがあるのではないかと思います。
そこで大豆を原料とする肉代替素材開発に関する国内の市場、特許、研究開発の動向について調査しました。
調査結果要約:2021年をピークとして大豆ミートへの関心は低下傾向にありますが、ニュース記事での企業活動は活発で、大豆ミートと謳わなくても業務用の食品素材としての需要は高まりそうです。2023年は大豆ミートとしての大豆タンパクの組織形成、成型技術は民間の研究者がリードし、市場への普及に関するマーケティング的な研究は大学の研究者が論文を公開していました。今後、消費者の理解がさらに進み、大きな話題となる食品の出現が期待されます。
市場の関心と動向
市場動向を調査するために、Google Trendsによる関心の推移、Google newsデータを分析しました。
Google Trends
Google TrendsではGoogle検索頻度の相対的推移がデータ化されています。
2022年ごろから「大豆ミート」へのGoogle Trendsは下降傾向です。少なくとも「大豆ミート」というワードへの関心は低くなっているように見えます。
一方、2023年に急上昇した関連キーワードには、「SDGS企業」、「常備菜レシピ」、「謎肉 大豆」、「やよい軒 大豆ミート」などがあります。このあたりが大豆ミートへの関心の高まりと普及拡大へのヒントになりそうです。
常備野菜レシピ
「常備野菜レシピと大豆ミート」でGoogle検索するとCOOKPADとクラシルのページがヒットしました。
みんなの「大豆たんぱく 作り置き」レシピが64品 常備菜にも!10分で完成 プルコギ風旨辛やみつき丼 - クラシル謎肉 大豆ミート
「謎肉 大豆ミート」でGoogle 検索すると下記のページがヒットしました。カップヌードルの謎肉で世界中に広まると良いですね。
売上4千億円、カップヌードル「謎肉」製造…不二製油、有名すぎる黒子企業の秘密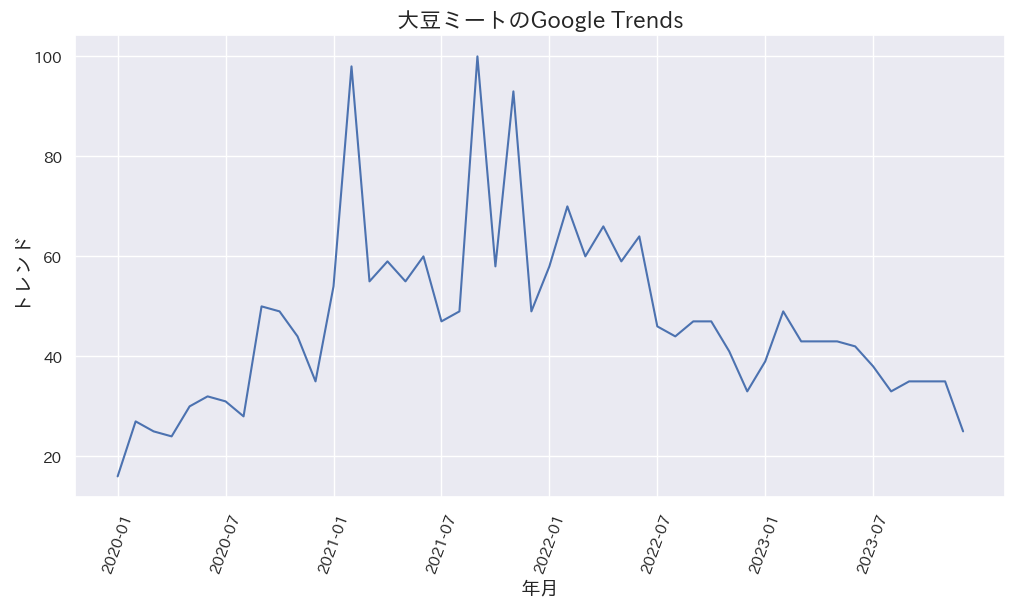
Google ニュース
Google ニュースはキーワードに関係する最新のネット記事を100件程度表示してくれます。
大豆ミートの市場に関する記事を検索すると92件の記事がヒットしました。
大豆ミートの販売動向に関する記事がありました。
この記事によれば、2022年まで急速に拡大していた市場規模が減少に転じているそうです。
一方では大豆ミート協会発足の記事が12件ありました。業界としての大きな動きです。設立メンバーは、マルコメ、スターゼン、伊藤ハム米久ホールディングス、日本ハム、大塚食品の5社です。
日本大豆ミート協会
大豆ミート供給企業では、アジアンテック・ファインフーズ、DAIZ社などの記事がありました。
大豆ミート、大豆蛋白を利用した食品をリリースした大手の食品企業・大手流通には、キューピー、ケンコーマヨネーズ、亀田製菓、日清食品、セブンイレブン、マルコメ、コストコなどの記事がありました。企業活動は活発なようです。
特許
大豆ミートに関する特許推移
J-PlatPatでの検索。
検索式:[肉代替/AB+代替肉/AB+肉様/AB]*[大豆/AB](*ABは要約)。
公知年で出願数推移では2023年は前年より減少しています。
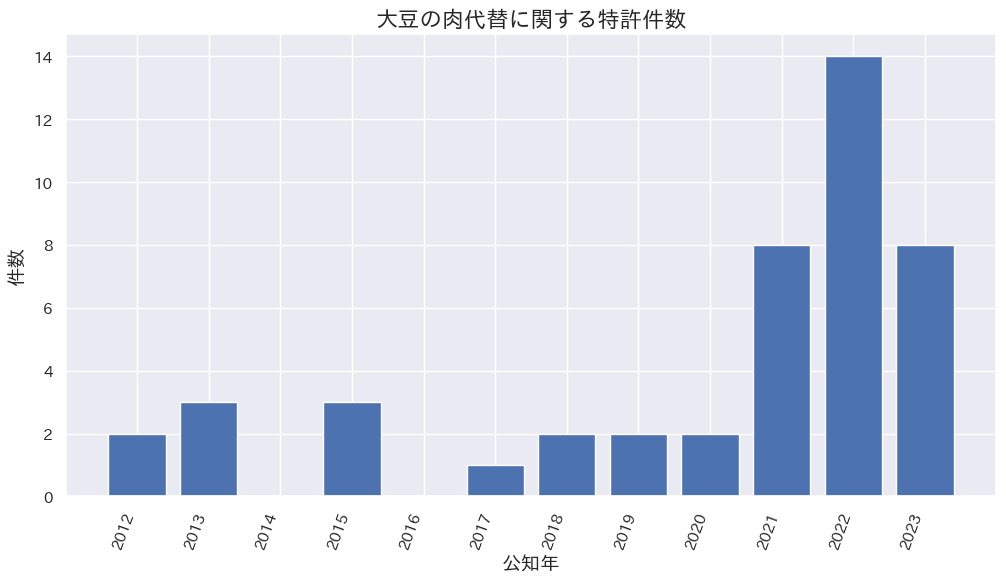
2023年公知された特許の出願者と公知件数
- イビデン株式会社 : 4
- 株式会社みすずコーポレーション : 2
- 日本ハム株式会社 : 1
- ミヨシ油脂株式会社 : 1
組織形成・食感に関する特許が6件、風味・苦み改善が1件、健康機能が1件でした。組織形成・食感改良に力を入れているのがわかります。
文献からの研究動向
検索条件
J-GLOBALでフリーワード:大豆 and (ミート or 肉代替 or 代替肉)
発行年:2019年〜2023年
今回は日本の発行機関の文献のみの検索。次回からは海外文献で日本人が著者に含まれている文献にも検索を拡大する予定です。
2023年は登録の遅れで件数が少なくなっているかもしれません。
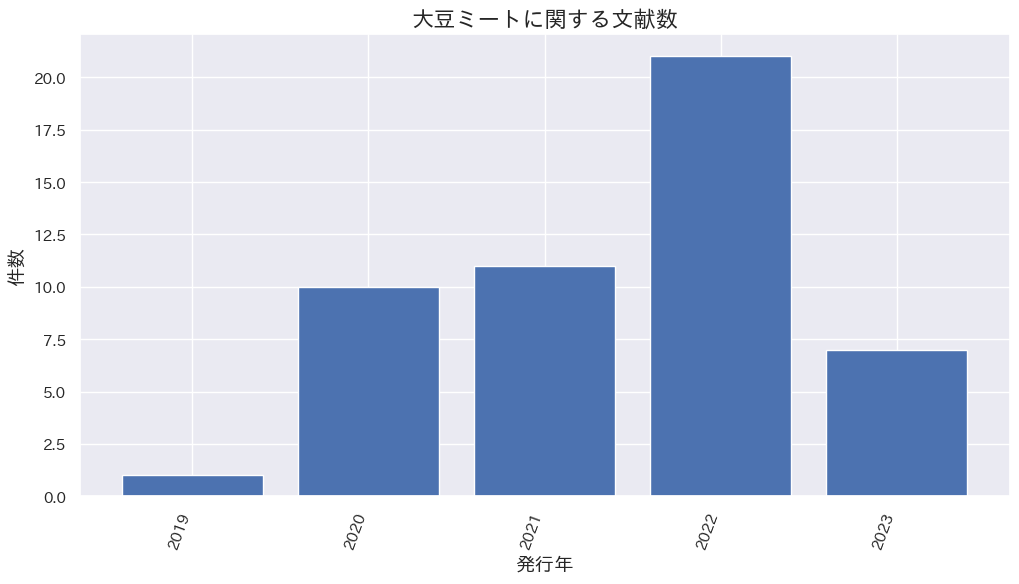 J-Globalでの大豆ミートに関する2023年の文献検索結果
J-Globalでの大豆ミートに関する2023年の文献検索結果
大豆ミートの需要要因に関する文献が3件、大豆ミートの成型や粒状タンパクの開発に関する文献が2件ヒットしました。
大豆ミート需要要因に関する文献
2件とも民間と大学の研究者の共著です。
情報供与が大豆ミート需要に与える影響最近の代替肉への関心高まりを受け、本研究では植物性(大豆)食肉に対する支払い意思を調査。混合ロジットモデルによる推計では、植物性食肉に対する支払い意欲は牛肉と同等で、味や非遺伝子組み換え情報の提供が重要。環境情報提供時には支払い意思が増加する傾向が見られた。
Exploring Japanese Consumers’ Motivators Related to Eating Soy Meat(大豆ミートを食べることに関する日本の消費者の動機付けの調査)本研究では、ロジスティック回帰分析を通じて、大豆ミートの消費に関連する日本の消費者の動機を調査し、食への親近感、環境への配慮、利便性、官能的魅力が大豆ミートの消費頻度に影響を与えることが明らかにされた。特に、利便性と官能的魅力は食品企業がコントロールできる要因であり、これらに焦点を当てれば日本の大豆ミート市場の拡大が期待される。
大豆ミートの成型や粒状タンパクの開発に関する文献
いずれも民間の研究者によるレビューです。
食のイノベーションに資する化学工学 粒状大豆たん白の開発と大豆ミートへの応用非プラスチックの成形技術 食品の成形大豆ミートと粒状大豆たん白
プロテインクライシスに対するフードテックの挑戦-現状と今後の展望-粒状大豆たん白の開発と大豆ミートへの展開
大豆ミート製品「ゼロミート」の開発について
Pythonによるプログラムコード
あくまで参考です。自己責任で適当に編集して試してください。
開発・実行環境: Google Colaboratory
Google newsデータの収集
# install
!pip install feedparser
# import
import feedparser
import urllib
import pandas as pd
import pprint
# 検索年月日と検索ワード
s_01 = '大豆ミート'
## 検索ワードをURLエンコードに変換
s_01_quote = urllib.parse.quote(s_01)
## グーグルニュース検索のURLの間に挟む
url_01 = "https://news.google.com/news/rss/search/section/q/" + s_01_quote + "/" + s_01_quote + "?ned=jp&hl=ja&gl=JP"
# Google newsデータの収集
d_01 = feedparser.parse(url_01)
title_l = []
published_l = []
sortkey_l = []
link_l = []
for i, entry in enumerate(d_01.entries, 1):
p = entry.published_parsed
sortkey = "%04d%02d%02d%02d%02d%02d" % (p.tm_year, p.tm_mon, p.tm_mday, p.tm_hour, p.tm_min, p.tm_sec)
title_l.append(entry.title)
published_l.append(entry.published)
sortkey_l.append(sortkey)
link_l.append(entry.link)
df_01 = pd.DataFrame({'title': title_l, 'published': published_l, 'sortkey': sortkey_l, 'link': link_l})
print(df_01.info())
# sortkeyでソート(年月日順に)
df_01_sort = df_01.sort_values('sortkey', ascending=False)
# index 振り直し
df_01_sort.reset_index(drop=True, inplace=True)
print(df_01_sort.head())
# csvで保存
filename = 'gnews' + ymd + '.csv'
df_01_sort.to_csv(filename, index=False)
J-GLOBALの検索結果をダウンロードしたBibTeXファイルをcsvファイルに変換
プログラミング交流サイトのqiitaへアップしてあります。
BibTexファイルのcsvへの変換
# install
!pip install --pre bibtexparser
# import
import bibtexparser
import pandas as pd
# 関数定義
def bib_to_df(bib_file):
library = bibtexparser.parse_file(bib_file)
title_l = []
note_l = []
author_l = []
journal_l = []
year_l = []
volume_l = []
DOI_l = []
for entry in library.entries:
title_l.append(entry['title'])
note_l.append(entry['note'])
author_l.append(entry['author'])
journal_l.append(entry['journal'])
year_l.append(entry['year'])
volume_l.append(entry['volume'])
DOI_l.append(entry['DOI'])
df = pd.DataFrame({
'title': title_l,
'note': note_l,
'author': author_l,
'journal': journal_l,
'year': year_l,
'volume': volume_l,
'DOI': DOI_l
})
return df
# 関数を実行してcsvファイルで保存
## file path
fname = 'ダウンロードしたファイル名を'
bib_file = 'input/' + fname + '.bib'
csv_file = 'output/' + fname + '.csv'
## 関数実行してデータフレームへ
df = bib_to_df(bib_file)
print(df.shape)
print(df.info())
display(df.head())
## csvファイルへ保存
df.to_csv(csv_file, index=False)